Transforming a Docx with Hierarchical Numbering into Different XML
The new ListItemRetriever.cs module in PowerTools for Open XML enables us to find out lots of information about the numbered and bulleted lists in our documents. We can write a small amount of code and transform a DOCX that contains hierarchical numbered lists into an alternative form of XML. For instance, we may want to transform a document that looks like this:
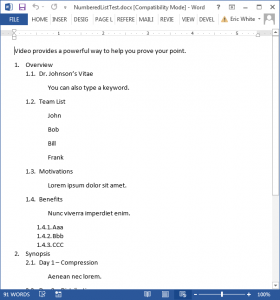
Into XML that looks like this:
<?xml version="1.0" encoding="utf-8"?>
<Root>
<Paragraph>Video provides a powerful way to help you prove your point.</Paragraph>
<Indent Level="1">
<Heading>Overview</Heading>
<Indent Level="1.1">
<Heading>Dr. Johnson’s Vitae</Heading>
<Paragraph>You can also type a keyword.</Paragraph>
</Indent>
<Indent Level="1.2">
<Heading>Team List</Heading>
<Paragraph>John</Paragraph>
<Paragraph>Bob</Paragraph>
<Paragraph>Bill</Paragraph>
<Paragraph>Frank</Paragraph>
</Indent>
<Indent Level="1.3">
<Heading>Motivations</Heading>
<Paragraph>Lorem ipsum dolor sit amet.</Paragraph>
</Indent>
<Indent Level="1.4">
<Heading>Benefits</Heading>
<Paragraph>Nunc viverra imperdiet enim.</Paragraph>
<Indent Level="1.4.1">
<Heading>Aaa</Heading>
</Indent>
<Indent Level="1.4.2">
<Heading>Bbb</Heading>
</Indent>
<Indent Level="1.4.3">
<Heading>CCC</Heading>
</Indent>
</Indent>
</Indent>
<Indent Level="2">
<Heading>Synopsis</Heading>
<Indent Level="2.1">
<Heading>Day 1 – Compression</Heading>
<Paragraph>Aenean nec lorem.</Paragraph>
</Indent>
<Indent Level="2.2">
<Heading>Day 2 – Distribution</Heading>
<Paragraph>In porttitor.</Paragraph>
</Indent>
<Indent Level="2.3">
<Heading>Day 3 – Time Line</Heading>
<Paragraph>Donec laoreet nonummy augue.</Paragraph>
</Indent>
</Indent>
<Indent Level="3">
<Heading>Technical Details</Heading>
<Indent Level="3.1">
<Heading>Engine</Heading>
</Indent>
<Indent Level="3.2">
<Heading>Passenger Compartment</Heading>
</Indent>
<Indent Level="3.3">
<Heading>Trunk</Heading>
</Indent>
<Indent Level="3.4">
<Heading>Tires</Heading>
</Indent>
</Indent>
<Indent Level="4">
<Heading>Summary</Heading>
<Indent Level="4.1">
<Heading>Contraindications</Heading>
</Indent>
<Indent Level="4.2">
<Heading>Index</Heading>
</Indent>
</Indent>
</Root>
The ListItemRetreiver assembles all kinds of information about each item in a numbered list, and it is easy to retrieve this information – it is stored as annotations on the paragraph XML elements after calling ListItemRetriever.RetrieveListItem. The following code accomplishes the above transform:
/***************************************************************************
Copyright (c) Microsoft Corporation 2014.
This code is licensed using the Microsoft Public License (Ms-PL). The text of the license
can be found here:
http://www.microsoft.com/resources/sharedsource/licensingbasics/publiclicense.mspx
***************************************************************************/
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Xml.Linq;
using DocumentFormat.OpenXml.Packaging;
using OpenXmlPowerTools;
class ListItemRetriever01
{
private class XmlStackItem
{
public XElement Element;
public int[] LevelNumbers;
}
/*
* This example loads each document into a byte array, then into a memory stream,
* so that the document can be opened for writing without modifying the source document.
*/
static void Main(string[] args)
{
var thisDir = new DirectoryInfo(".");
foreach (var xmlFile in thisDir.GetFiles("*.xml"))
xmlFile.Delete();
using (WordprocessingDocument wDoc =
WordprocessingDocument.Open("../../NumberedListTest.docx", false))
{
int abstractNumId = 0;
XElement xml = ConvertDocToXml(wDoc, abstractNumId);
Console.WriteLine(xml);
xml.Save("Out.xml");
}
Console.WriteLine("Press Enter");
Console.ReadKey();
}
private static XElement ConvertDocToXml(WordprocessingDocument wDoc, int abstractNumId)
{
XDocument xd = wDoc.MainDocumentPart.GetXDocument();
// First, call RetrieveListItem so that all paragraphs are initialized with ListItemInfo
var firstParagraph = xd.Descendants(W.p).FirstOrDefault();
var listItem = ListItemRetriever.RetrieveListItem(wDoc, firstParagraph);
XElement xml = new XElement("Root");
var current = new Stack<XmlStackItem>();
current.Push(
new XmlStackItem()
{
Element = xml,
LevelNumbers = new int[] { },
});
foreach (var paragraph in xd.Descendants(W.p))
{
// The following does not take into account documents that have tracked revisions.
// As necessary, call RevisionAccepter.AcceptRevisions before converting to XML.
var text = paragraph.Descendants(W.t).Select(t => (string)t).StringConcatenate();
ListItemRetriever.ListItemInfo lii =
paragraph.Annotation<ListItemRetriever.ListItemInfo>();
if (lii.IsListItem && lii.AbstractNumId == abstractNumId)
{
ListItemRetriever.LevelNumbers levelNums =
paragraph.Annotation<ListItemRetriever.LevelNumbers>();
if (levelNums.LevelNumbersArray.Length == current.Peek().LevelNumbers.Length)
{
current.Pop();
var levelNumsForThisIndent = levelNums.LevelNumbersArray;
string levelText = levelNums
.LevelNumbersArray
.Select(l => l.ToString() + ".")
.StringConcatenate()
.TrimEnd('.');
var newCurrentElement = new XElement("Indent",
new XAttribute("Level", levelText));
current.Peek().Element.Add(newCurrentElement);
current.Push(
new XmlStackItem()
{
Element = newCurrentElement,
LevelNumbers = levelNumsForThisIndent,
});
current.Peek().Element.Add(new XElement("Heading", text));
}
else if (levelNums.LevelNumbersArray.Length > current.Peek().LevelNumbers.Length)
{
for (int i = current.Peek().LevelNumbers.Length;
i < levelNums.LevelNumbersArray.Length;
i++)
{
var levelNumsForThisIndent = levelNums
.LevelNumbersArray
.Take(i + 1)
.ToArray();
string levelText = levelNums
.LevelNumbersArray
.Select(l => l.ToString() + ".")
.StringConcatenate()
.TrimEnd('.');
var newCurrentElement = new XElement("Indent",
new XAttribute("Level", levelText));
current.Peek().Element.Add(newCurrentElement);
current.Push(
new XmlStackItem()
{
Element = newCurrentElement,
LevelNumbers = levelNumsForThisIndent,
});
current.Peek().Element.Add(new XElement("Heading", text));
}
}
else if (levelNums.LevelNumbersArray.Length < current.Peek().LevelNumbers.Length)
{
for (int i = current.Peek().LevelNumbers.Length;
i > levelNums.LevelNumbersArray.Length;
i--)
current.Pop();
current.Pop();
var levelNumsForThisIndent = levelNums.LevelNumbersArray;
string levelText = levelNums
.LevelNumbersArray
.Select(l => l.ToString() + ".")
.StringConcatenate()
.TrimEnd('.');
var newCurrentElement = new XElement("Indent",
new XAttribute("Level", levelText));
current.Peek().Element.Add(newCurrentElement);
current.Push(
new XmlStackItem()
{
Element = newCurrentElement,
LevelNumbers = levelNumsForThisIndent,
});
current.Peek().Element.Add(new XElement("Heading", text));
}
}
else
{
current.Peek().Element.Add(new XElement("Paragraph", text));
}
}
return xml;
}
}
This example of the use of the ListItemRetriever module is important enough that I’ve incorporated it as one of the examples that I deliver as part of the Open XML PowerTools core examples.
One note about the above code – I didn’t write it in the pure functional style. I write it as procedural code that uses a stack. Previously, I had posted some LINQ code that took a recursive, functional approach. I am not sure which is more approachable for less experienced developers, but I suspect that the procedural approach that uses a stack might be easier.
This code isn’t data driven – it produces a specific XML structure that is hard coded into the example. It could be possible to convert this code to another more flexible form that could produce a variety of XML shapes. The code is only about 150 lines long – not too complicated, so it should be easy for developers to morph the code into a form that fits their scenario.
Cheers, Eric